LLM Inference Internals — Part 1: What Quantization Actually Costs You

With recent developments in LLM, I want to take a moment to pause and learn how it works internally. Coming from a backend engineering background, I want to understand the system side of LLM instead of the ML problem. That’s what excites me more. In this series, I want to go through LLM and the important components such as inference (serving a model at scale) and my learnings along the way, with some fun experiments.
First lets explore the basic of LLM inference by taking a look at Quantization.
What Is Quantization
LLMs are a set of neural networks (with attention mechanism) represented by weights. For example, when you load GPT-2, you’re loading 124 million of them. Each of the weights were learned during the training process.
By default those weights are stored as 32-bit floats (fp32). Each one takes 4 bytes. Multiply that out and GPT-2 weighs in at ~475 MB just to sit in memory. For larger models with 7B, 70B parameters, this memory gets out of hand fast.
Quantization is the idea that you don’t need that much precision. Most of those weights can be represented with fewer bits without meaningfully changing what the model outputs. fp16 halves each weight to 2 bytes. int8 gets it down to 1 byte. int4 squeezes two weights into a single byte.
My initial assumption was straightforward, if we use less memory with lower precision, the model should generate outputs faster, right? I wanted to validate this idea by running a small experiment.
Setup
Model: GPT-2 (124M parameters)
Hardware: Apple Silicon, PyTorch MPS backend
Prompts: short (~5 tokens), medium (~50 tokens), long (~200 tokens)
Measurement: one warmup run discarded, three timed runs averaged
Results
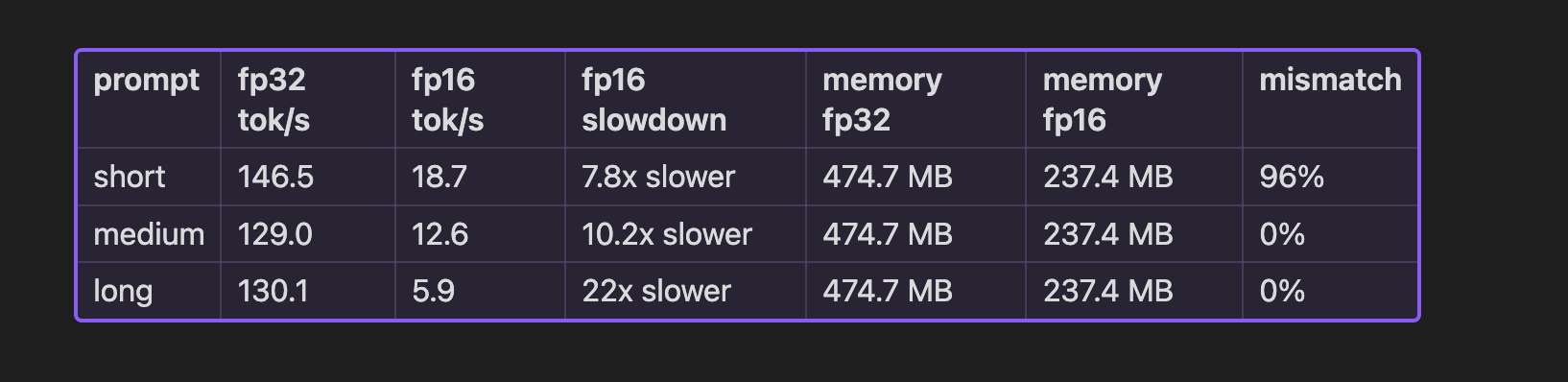
After running the benchmark, my understanding was challenged. From the memory foot print it was expected i.e 50% reduction when the model weight changed. Interesting part is when the token/s value. Model with lower precision weight should be able to generate faster outputs. But its not the case. Lets explore each case by case.
Memory Actually Halves
fp16 delivered exactly what it promised on memory — 237.4 MB versus 474.7 MB. Exactly half, because it literally is half the bytes per weight.
This holds regardless of hardware. It’s arithmetic, not an optimization. For stored weights at least, smaller dtype means smaller footprint, full stop.
For GPT-2 the saving is a few hundred megabytes — who cares. But for a 70B model it’s the difference between needing ~140 GB of VRAM or ~70 GB. That’s one H100 versus two. The memory case for quantization is real, even when the speed case isn’t.
fp16 Is Slower. A Lot Slower.
On NVIDIA, fp16 is fast because the hardware has Tensor Cores built specifically for fp16 matrix math. Going from fp32 to fp16 on CUDA means offloading work to faster silicon the speedup is real.
Apple Silicon’s MPS backend doesn’t work that way. fp16 operations often get upcast to fp32 internally to do the actual computation, then downcast back to fp16 to store the result. So you’re paying full fp32 compute cost, plus the overhead of converting back and forth on every operation. The longer the prompt, the more operations, the worse it gets which is why the slowdown goes from 8x on short prompts to 22x on long ones.
The Output Divergence Was Interesting
I measured how often fp16 and fp32 produce different tokens for the same prompt, using greedy decoding so there’s no randomness involved. The result split cleanly by prompt length:
Short prompt → 96% of tokens are different
Medium and long prompts → 0% different
The short prompt number looks alarming but there’s a reasonable explanation. With minimal context, the model’s probability distribution over the vocabulary is spread out, lots of tokens with similar probabilities. fp16’s rounding error is enough to tip one token above another. Once that first token differs, every token after it is conditioned on different context. The divergence compounds.
Longer prompts constrain the model more. The next token has a clear probability lead and fp16’s error isn’t big enough to close the gap. fp32 and fp16 agree, and keep agreeing.
So if I were building something with long system prompts, say a RAG pipeline or a chat assistant with detailed instructions fp16 is probably fine from a quality standpoint.
Next Up
Quantization is one way to make inference cheaper i.e reduce the weight precision, reduce the memory. But what if a smaller, faster model could do most of the generation work, and a larger model just verified it? That’s the idea behind speculative decoding, and that’s what Part 2 is about.